
はじめに
機械学習、盛り上がり続けてますね。今回はiOS/Androidで機械学習による解析が行えるFirebase ML Kitの勉強会に行ってきました。
実際に会場で試した内容を紹介したいと思います。とりあえず動かしてみるだけなら簡単ですので、Android実機をお持ちであれば、ぜひ試してみてください。
Firebase ML Kitとは
- Google IO 2018で発表されたFirebaseの新機能です。現在はベータ版で、iOSおよびAndroid両方の端末で利用できます。
- Googleが提供する機械学習モデルによる解析APIを、on-device APIもしくはcloud-based APIから利用できます(後者のほうが高精度、ただし有料)。
- on-device API:
デバイス上で解析処理を行います。オフラインでも実行でき、高速です。ただしテキスト認識はlatin-based language(アルファベットを使う言語)のみ対象で、ラベル付けもあまり細かく分類はできないようです。 - cloud base API:
Firebaseの有料プラン(Blaze)が必要ですが、多言語でのテキスト認識や、より詳細なラベル付けが可能です(機能ごとに1000コールまでは無料)。 - できること
機能 on-device cloud テキスト認識 ○ ○ 画像を読み込んでテキスト抽出 顔検出 ○ × 画像を読み込んで人の顔を検出 バーコードスキャン ○ × そのまま。バーコード読み取り。 画像のラベル付け ○ ○ 画像を読み込んでラベリング ランドマーク認識 × ○ 画像内のランドマーク(東京タワー、スカイツリーetc.)を認識 カスタムモデルの利用 ○ × 独自のTensorflow LiteモデルをFirebaseにアップロードして、アプリで使える - 参考
Firebase 向け ML Kit | モバイル デベロッパー向けの機械学習
I/O Recap : ML Kit 情報まとめ(Android 向け)
準備するもの
エミュレータでも動作するので実機必須ではありませんが、できれば実機でいろいろ写真を撮って試すのをおすすめします。
- macOS High Sierra 10.13.6
- AndroidStudio 3.0.1
- githubアカウント
サンプルプロジェクトをcloneするのに必要です。 - Googleアカウント
Firebaseを使うために必要です。
動かすまでの手順
https://github.com/yanzm/MLKitSample からgit cloneして、課題1・課題2までを終えれば準備完了です。
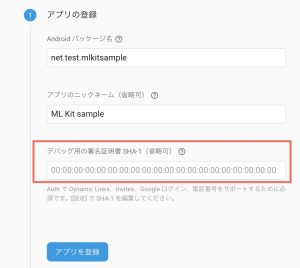
課題2-1で「デバッグ用の署名証明書」は省略可ですので、空欄のままでOKです。
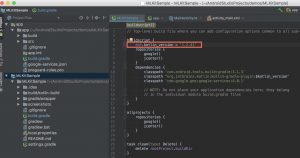
gradleのsyncがうまくいかない場合
会場で私を含め何人かが遭遇していた現象で、AndroidStudioが最新版(3.1.3)になっていないことが原因だったようです。
素直にAndroidStudioをバージョンアップしてもいいのですが、Kotlinのバージョン指定を書き換えることでもひとまず解決できます。
私の場合(3.0.1)では、build.gradleに記述されているKotlinのバージョンを
1.2.51
から
1.2.41
に変更することで、syncできるようになりました。
テキスト認識を試してみる
画像を読み込み、テキストを抽出します。
MainActivity.kt#detect
に下記リンクからコードを追加します。
課題3 : テキスト認識
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | private fun detect(bitmap: Bitmap) { overlay.clear() val detectorName = detectorSpinner.selectedItem as String when (detectorName) { TEXT_DETECTION -> { // TODO: 1 on-device テキスト認識 // https://firebase.google.com/docs/ml-kit/android/recognize-text#on-device detectButton.isEnabled = false progressBar.visibility = View.VISIBLE val image = FirebaseVisionImage.fromBitmap(bitmap) FirebaseVision.getInstance() .visionTextDetector .detectInImage(image) .addOnSuccessListener { texts -> detectButton.isEnabled = true progressBar.visibility = View.GONE for (block in texts.blocks) { for (line in block.lines) { for (element in line.elements) { element.boundingBox?.let { overlay.add(BoxData(element.text, it)) } } } } } .addOnFailureListener { e -> detectButton.isEnabled = true progressBar.visibility = View.GONE e.printStackTrace() } } FACE_DETECTION -> { ... |
firebaseのwebページを実機で撮影、処理してみると以下のようになります(on-deviceのため、日本語は認識できません)。
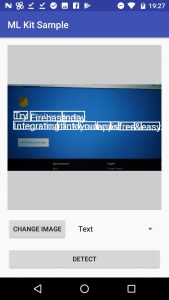
文字が重なっててよくわからない!という場合は、
GraphicOverlay.kt
内の
textSize
を変更してみましょう。
| 1 2 3 4 | private val textPaint = Paint().apply { color = Color.WHITE textSize = 20 * resources.displayMetrics.density } |
画像のラベル付けを試してみる
画像を読み込み、何が写っているのかを解析・表示します。
MainActivity.kt#detect
に、下記リンクからコードを追加します。
課題7 : 画像のラベル付け
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | private fun detect(bitmap: Bitmap) { overlay.clear() val detectorName = detectorSpinner.selectedItem as String when (detectorName) { // 中略 LABELING -> { // TODO: 4 on-device ラベルづけ // https://firebase.google.com/docs/ml-kit/android/label-images#on-device detectButton.isEnabled = false progressBar.visibility = View.VISIBLE val image = FirebaseVisionImage.fromBitmap(bitmap) val options = FirebaseVisionLabelDetectorOptions.Builder() .setConfidenceThreshold(0.5f) // スコア0.5未満は解析結果に表示しない .build() FirebaseVision.getInstance() .getVisionLabelDetector(options) .detectInImage(image) .addOnSuccessListener { labels -> detectButton.isEnabled = true progressBar.visibility = View.GONE overlay.add(TextsData(labels.map { "${it.label}, ${it.confidence}" })) } .addOnFailureListener { e -> detectButton.isEnabled = true progressBar.visibility = View.GONE e.printStackTrace() } } } |
「Tableware」「Cutlery」等がラベル名です。その横の数字はラベルのスコアで、1.0に近づくほど確度が高いことを意味しています。スコアが
0.9
を超えるラベルはほぼ間違いがなく、0.8でも大体合っているという印象です。

Cloud API、カスタムモデルの利用
多言語対応のテキスト認識や高精度のラベル付け、またランドマーク認識などを処理できますが、こちらはまだ試していません。近い内に試してみて、ご紹介したいと思います。
カスタムモデルについてはきちんと理解できているか怪しいですが、TensorFlow Liteの独自モデルを使うことで、テキスト認識や画像のラベル付けで、より個々の目的に特化した解析ができるようになるのだと思います。
興味はありつつ後回しにしていた機械学習ですが、少し学んでみたいと思っています。
さいごに
いかがでしたでしょうか。私は機械学習と言われるものに触れるのは今回が初めてでしたが、驚くほど簡単に試すことができました。
試して遊ぶ分には面白いのですが、実案件で使うものではないという印象です(まだベータ版ですし…)。
また、アプリと一緒にカスタムモデルを端末に入れて解析に使うこともできますが、root化された端末ではモデルの中身を覗けてしまう可能性があったりと、Googleの中の人いわく「セキュリティについてはこれから検討していく」とのことでした。

