
はじめに
皆さんは、GraphQLを実際に使ったことがありますか?私は幸いなことに、業務で使う機会がありましたので、調べてみました。今回の記事では、GraphQLの概要について紹介します。
GraphQLとは?
GraphQLを一言で言い表すと、「APIからデータを取得するためのクエリ言語」と言えるのではないでしょうか。一般的にGraphQLでは、RESTなどと同じように、HTTPプロトコルでリクエストされます。
既にRESTが普及しているのに、なぜ、GraphQLが誕生したのか、疑問に思うかもしれません。GraphQL誕生の経緯について紹介します。
なぜGraphQLは誕生した?
GraphQLが誕生したきっかけを知るには、まず、RESTの欠点を見てみるのが良いでしょう。
RESTの欠点を3つ挙げます。
- 過剰な取得
- 過少な取得
- エンドポイントの管理
過剰な取得
とある書店の在庫検索システムを例に見てみます。JavaScriptを含む本を検索するAPIのレスポンスとして、以下のようのJSONが返却されたとします。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | [ { "id": 1, "title": "実践JavaScript", "published_at": "2010/1/15", "author": { "id": 1, "name": "山田太郎" }, "publisher": { "id": 1, "name": "田中出版社", "zip": "xxx-xxxx", "address": "東京都新宿区〜", "tel": "03-1234-1234" }, "status": "入荷待ち", "stock": 0, "arrive_date": "2021/4/15", "price": 1500 } ] |
しかし、実際に画面に表示されるのがタイトル、出版社名、著者、在庫数、価格のみだったとすると、多くの不要なパラメータが返却されることになり、パフォーマンス悪化の原因になります。
過少な取得
過少な取得は過剰な取得の逆で、必要なパラメータが1度に返却できないことにより、複数回のリクエストが発生することです。
先ほどの例の在庫検索システムで、新たに著者ごとの関連書籍を表示することになった場合、著者の人数分だけ書籍一覧を取得するAPIをリクエストする必要があります。
エンドポイントの管理
先に挙げた、過剰な取得、過少な取得によるパフォーマンス悪化を改善する方法として、必要に応じて必要最低限のデータを返却するAPIを定義する方法があります。この場合、メンテナンスしなければならないAPIの数が増えることにより、開発工数が膨らみます。
GraphQLのメリットとデメリット
GraphQLを導入することによる、メリットとデメリットを見ていきます。
GraphQLのメリット
メリットとしては、先ほど挙げたRESTの欠点をカバーしていることの他に、リクエストを見れば、どんなレスポンスが返ってくるのかが一目でわかることが挙げられます。
例えば、例で挙げた在庫検索システムで、タイトル、出版社名、著者、在庫数、価格を取得するクエリは下記のとおりです。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | { books { title stock price author { name } publisher { name } } } |
この通り、レスポンスの形式がひと目でわかります。
GraphQLのデメリット
逆に、GraphQLのデメリットとしては、エンドポイントが一つのため、パフォーマンスの分析が難しいこと。動画などの大きなバイナリのアップロードが難しいなどのデメリットがあります。
GraphQLの言語仕様
GraphQLの言語使用において重要な要素を3つ挙げます。
- スキーマ
- クエリ
- リゾルバ
スキーマ
GraphQLを使うにあたり、データを仮想的な情報のグラフと捉えると、理解しやすいと思います。情報の入ったエンティティは型と呼ばれ、それぞれの型は、フィールドを通して互いに関連します。
データの取得はクエリによって行われ、クエリは、ルートから順にグラフを辿りながら必要なデータを見つけます。
このエンティティはスキーマで定義されます。先ほどの在庫検索システムを例に、スキーマを見てみましょう。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | schema { query: Query } type Query { books: [Book] } type Book { id: Int! title: String! published_at: String! author: Author! publisher: Publisher! status: String! stock: Int! arrive_date: String price: Int } type Author { id: Int! name: String! } type Publisher { id: Int! name: String! zip: String! address: String! tel: String! } |
GraphQLでは、複数のデフォルト型が付属しています。その中でも、一般的なのはスカラー型で、5つの型があります。
- ID:一意の識別子を使ってフィールドを定義する
- Int:符号付き32ビット整数
- Float:符号付き倍精度浮動小数点
- String:UTF−8文字シーケンス
- Boolean:true もしくは false
また、これの他にカスタム型を定義できます。Book型、Author型、Publisher型がこれにあたります。
最初に出てきたQuery型は、参照するデータ照会ポイントを定義するために使用します。ここでは、booksというデータ照会ポイントを定義しています。データ照会ポイントとデータソースの接続は、後述するリゾルバで行われます。
クエリ
クエリは、Query型で定義したデータ照会ポイントからデータを取得するために使用します。
例で挙げた在庫検索システムで、タイトル、出版社名、著者、在庫数、価格を取得するクエリは下記のとおりです。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | { books { title stock price author { name } publisher { name } } } |
この通り、レスポンスの形式がひと目でわかります。
リゾルバ
リゾルバは、データ照会ポイントをマッピングして、リクエストされたエンティティを返す関数です。リゾルバの実装は言語ごとに異なりますが、データソースが書籍の配列である場合のデータ照会ポイントのリゾルバは、下記のようになります。
| 1 2 3 | function () { return books; } |
実際にGraphQLでデータを取得する
公開されているGraphQLのAPIから、実際にデータを取得してみましょう。SWAPIからpersonのnameとgenderを取得してみます。
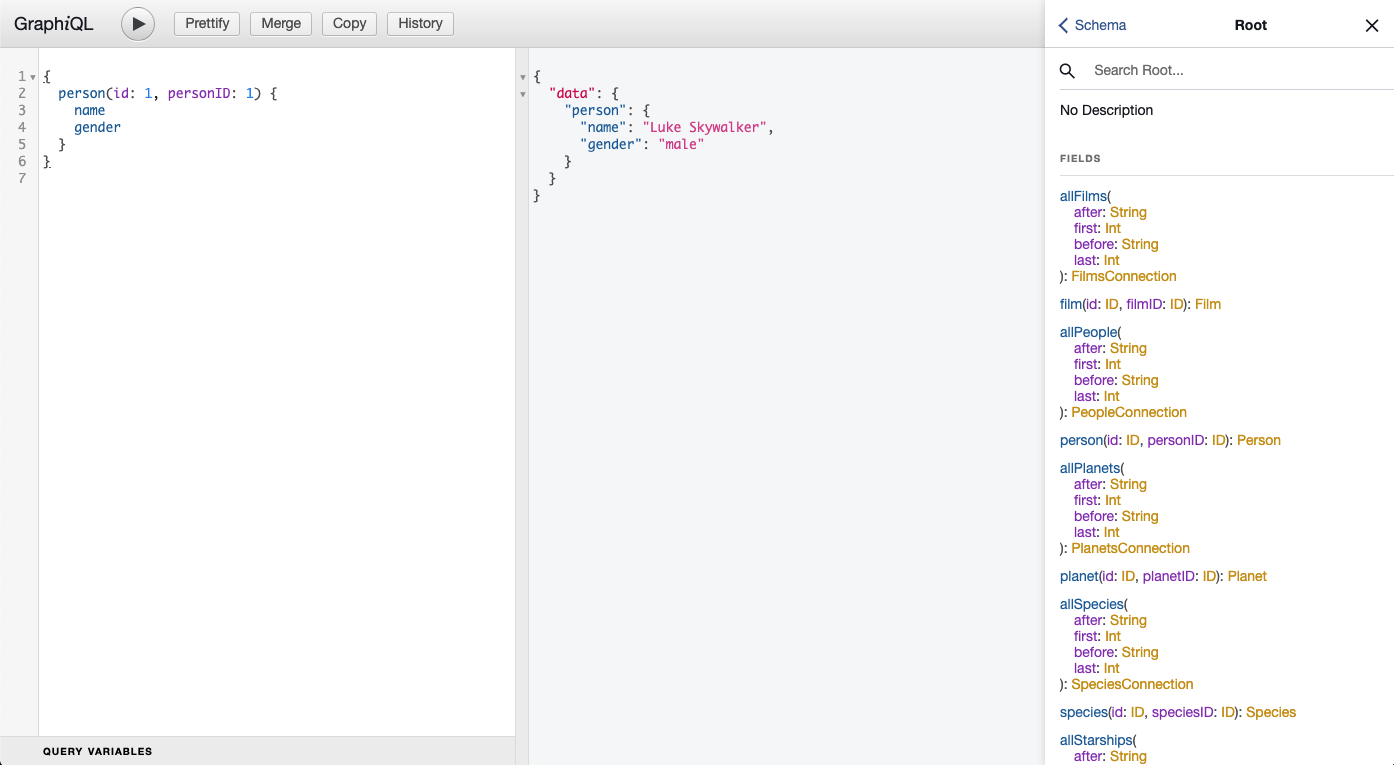
左側がクエリ、真ん中がレスポンス、右側がスキーマになります。このように、実際にGraphQLを使ってみることができます。
さいごに
今回は、GraphQLの概要について紹介しました。今後は、実装についても紹介できればと思います。
おすすめ書籍





