今回は、AWS Batchを実際に構築し、SaaSの非同期処理に向いているか検証したいと思います。
(Fargateを使用する場合の説明です。)
AWS Batch ダッシュボードの左メニューに有る「ウィザード」を使用すると、ステップに沿って環境構築を進めることができます。
今回はFargateを使用します。そのため、事前に実行されるDockerイメージをECRにPushしておく必要があります。
今回作成したDockerイメージはこちらです。
FROM golang:1.21-alpine WORKDIR /app COPY *.go ./ # Build RUN go build main.go # Run CMD ["./main"]
main.goの中身はこちらです。コマンドオプション -batchTypeを受け取ることができるようになっています。
package main
import (
"flag"
"fmt"
"os"
"time"
)
func main() {
batchType := flag.String("batchType", "", "Batch Type")
flag.Parse()
if batchType == nil || *batchType == "" {
fmt.Println("Please provide batchType")
os.Exit(1)
}
fmt.Println("Executing many many long tasks...", *batchType)
time.Sleep(10 * time.Second)
fmt.Println("Finished !!!")
}
これらを用意し、ローカル環境でdocker buildした上で、ECRに作成したリポジトリにPushします。
まずは、実行環境を選びます。GPUが必要など、特別なケースでなければ、Fargateが適していると思います。
コンピューティング環境設定では、名前を設定します。
インスタンス設定では、最大vCPUを設定します。Fargateを使用する場合は、ジョブごとにECSタスクが立ち上がるのですが、その各ジョブのvCPU数が、ここで指定する最大vCPU数を上回らないように調整してくれます。
もしも、ジョブがキューに送信され、コンピューティング環境のvCPU数にあまりがなければ、ジョブはRUNNABLE状態のままキューに保持されることになります。
このように、最大vCPUを適切に設定することで、ジョブの同時実行数を制御することができます。
ネットワーク設定では、VPCやセキュリティグループなどを選択します。ECSでFargateを使用する場合と同じように、エンドポイントの設定をしておく必要があります。(ECR、S3(ゲートウェイ型)、CloudWatchへのエンドポイントが必要です。)
ここでは、名前と優先度を設定します。ジョブキューごとに優先度を設定することで、優先度の高いジョブキューに入ったジョブから優先的に処理されます。
ジョブキューは先入れ先出し(FIFO)モデルですが、スケジュールポリシーを使用することでジョブの実行順序をカスタムすることもできます。
SQSほど高機能ではなく、例えばDLQのような機能や、同時実行数の設定などはできません。
(ただし、簡易的で良ければ、同時実行数に関しては最大vCPU数とジョブのvCPU数の調整で、似たようなことは実現できます。)
Fargateを使用した、ジョブ定義を作成していきます。基本的には、ECSタスク定義と似たような内容です。
Fargateの設定です。ランタイムプラットフォームの設定や、実行ロールなどを設定します。実行ロールには、ECSのタスク定義と同じく「ecsTaskExecutionRole」が必要です。作成されていない場合は、こちらを参考に作成してください。
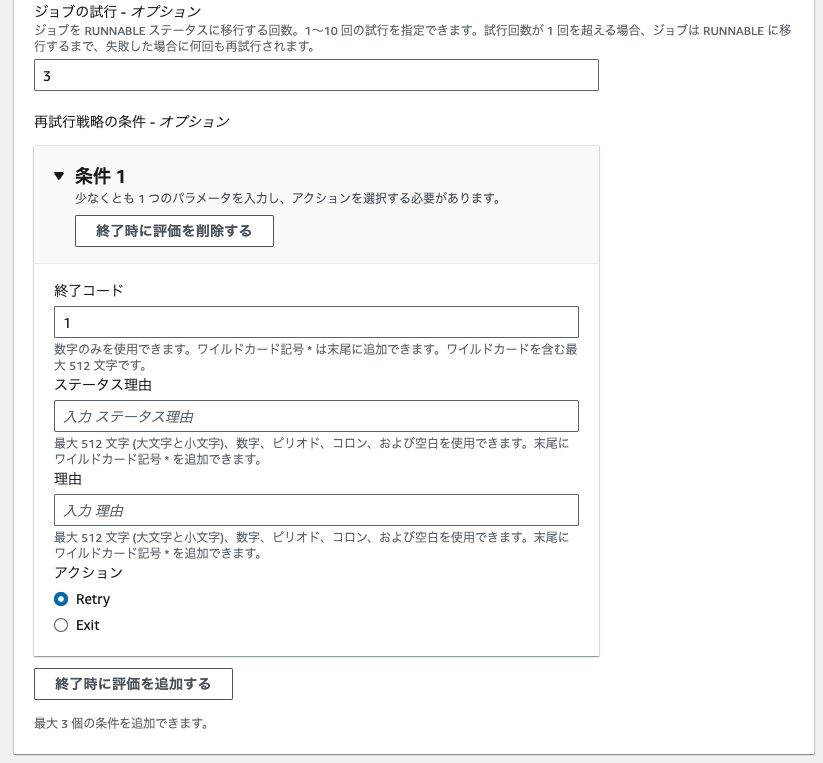
また、再試行戦略の条件を設定すると、終了コード等によって、RetryするかExitするか制御することもできます。
コンテナの設定では、使用するDockerイメージやコマンドを設定します。コマンドには Ref::foobarの形でプレースホルダーを書くことができ、ジョブの実行時にこれらをパラメータで上書きすることができます。
パラメータによる上書きは、ジョブ定義にも設定できますが、今回はジョブ実行時に渡せれば良いため、ここでは設定しません。
環境設定では、ジョブロール、vCPU/メモリ、環境変数/シークレットを設定します。
コンテナ内からAWSのリソースにアクセスする場合は、ジョブロールを設定しておきます。
シークレットは、Secret Managerシークレットか、Systems Manager パラメータストアの値が使用でき、いずれの場合でもARNで指定する必要があります。
ここまでで作成したリソースを使って、ジョブを実行してみます。今回は、Goからジョブを送信してみます。
package main
import (
"context"
"fmt"
"log"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/batch"
)
func main() {
cfg, err := config.LoadDefaultConfig(context.TODO(), config.WithRegion("us-east-2"))
if err != nil {
log.Fatalf("unable to load SDK config, %v", err)
}
client := batch.NewFromConfig(cfg)
jobName := "batch-go-job"
jobDefinition := "batch-go-job-definition"
jobQueue := "batch-go-job-queue"
output, err := client.SubmitJob(context.TODO(), &batch.SubmitJobInput{
JobName: &jobName,
JobDefinition: &jobDefinition,
JobQueue: &jobQueue,
Parameters: map[string]string{
"batchType": "someJobType",
},
})
if err != nil {
log.Fatalf("unable to submit job, %v", err)
}
fmt.Println(output.JobId)
}
clientSubmitJob()関数を使い、ジョブを送信します。第2引数にジョブの実行に必要な値を渡します。
Ref::foobarの形で指定したプレースホルダーを置き換える値を指定します。この他にも、ジョブ定義の内容を上書きすることができます。
ジョブの実行結果は、ダッシュボードから確認することができ、CloudWatch Logsの内容を確認することも可能です。
AWS Batchは、以下のような特徴があることが分かりました。
AWS Batchを構築するだけで以下の点が実現できるので、SaaSの非同期処理においては向いていると思いました。
逆に、上記のようなケースを実現する必要のない場合はオーバースペックなので、LambdaやECSタスクを直接起動する方法などを検討したほうが良いと思いました。
サービス選定にあたっては、以下の記事も参考になると思います。
https://zenn.dev/faycute/articles/fb310e3ccd783f
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}